
5 Programming Techniques to Avoid SSD Brick Catastrophic Failures

M
I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
Search for a command to run...
I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
No comments yet. Be the first to comment.
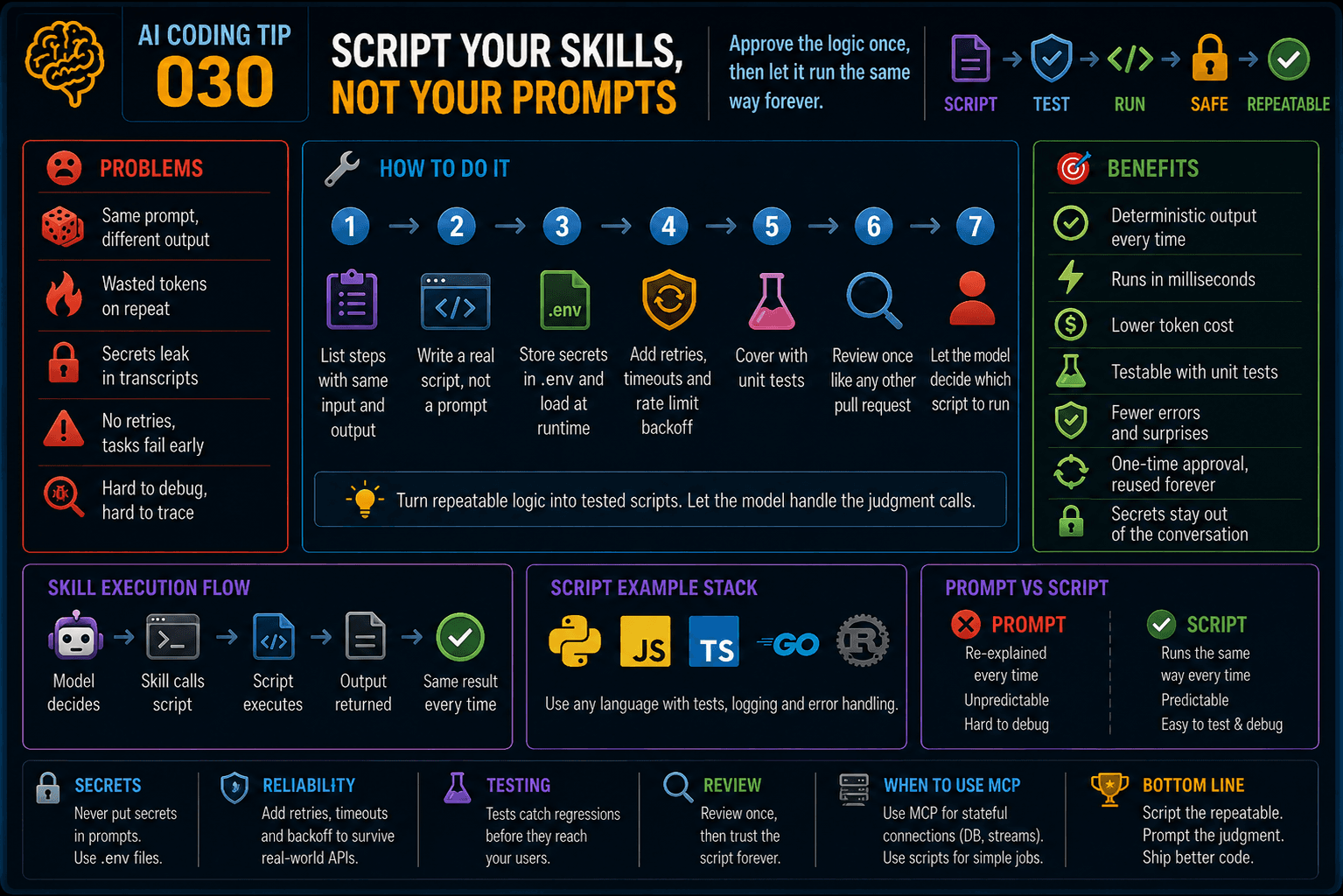
Approve the logic once, then let it run the same way forever.
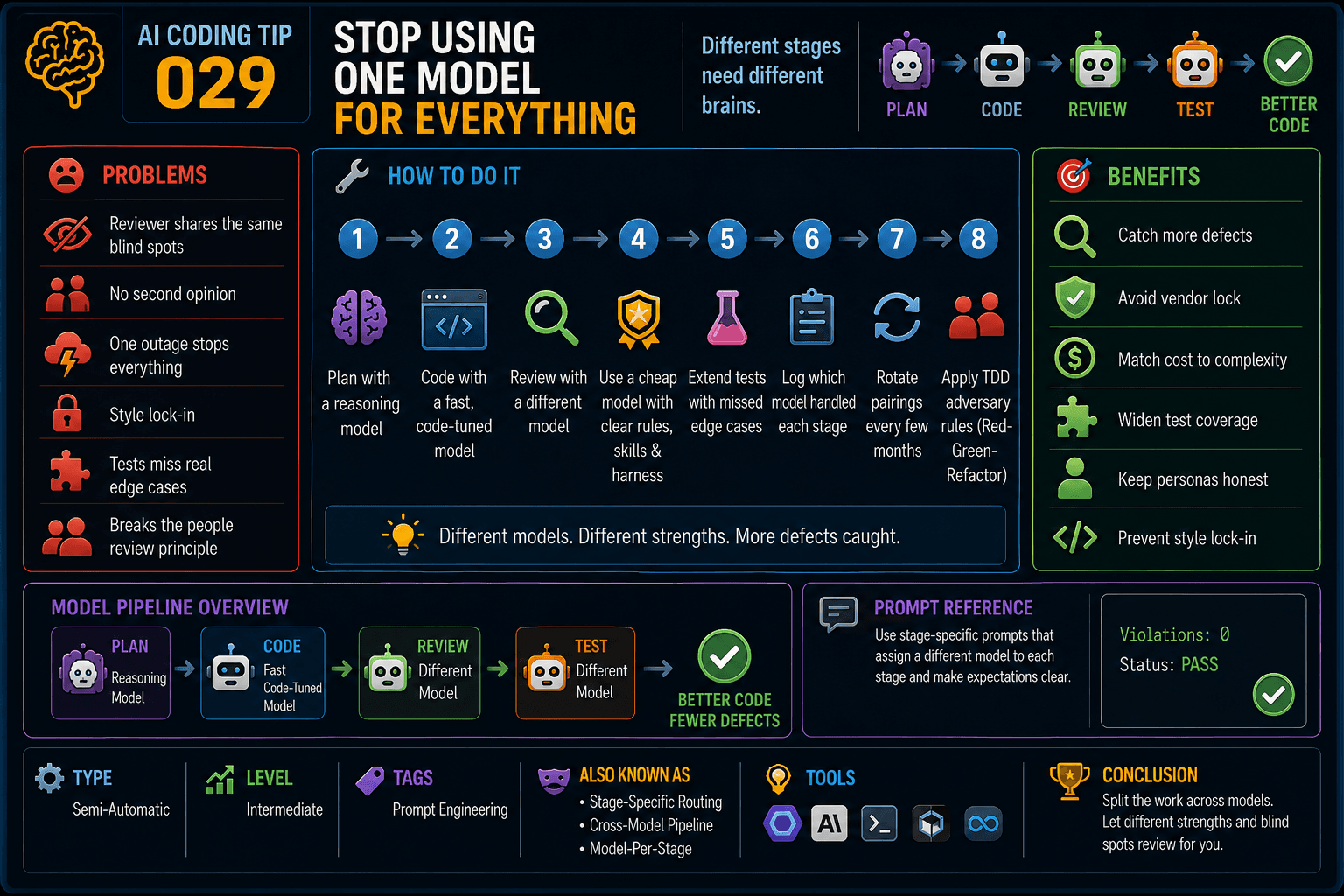
Different stages need different brains.
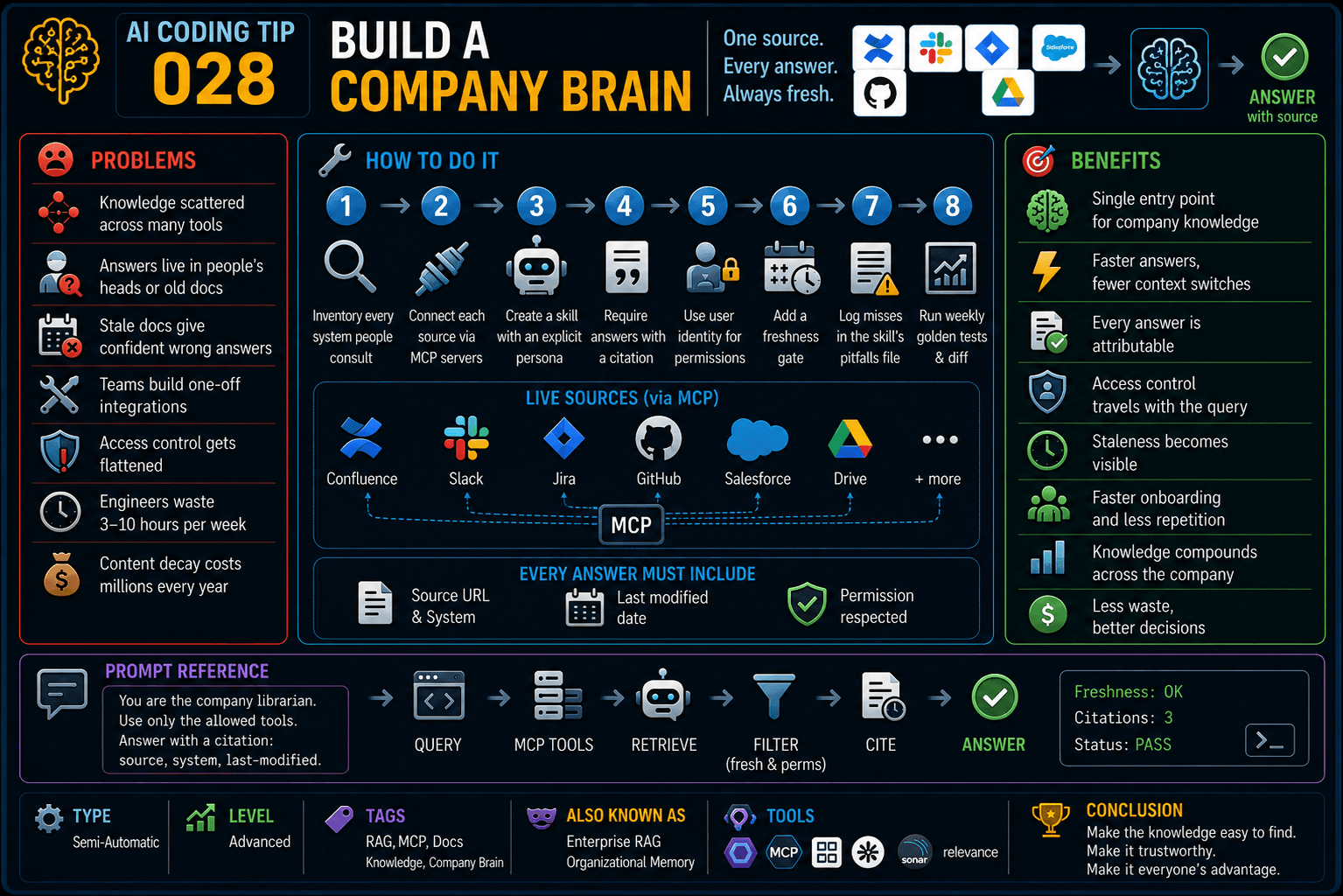
One Second Brain doesn't scale past one skull.
Style errors double when nobody enforces them.

Know who speaks before the skill runs TL;DR: Always define a clear role at the top of every skill file so you know whose perspective drives the execution. Common Mistake ❌ You write a skill full of

Preventing serious faults is within reach
TL;DR: Use mature tools to make mature software.
On July, 9th 2022, yet another hardware failure bricked several servers.
Looking at failure's root cause we can learn a lesson.
On this thread we can find what happened:
I once had a small fleet of SSDs fail because they had some uptime counters that overflowed after 4.5 years, and that somehow persistently wrecked some internal data structures. It turned them into little, unrecoverable bricks. It was not awesome seeing a bunch of servers go dark in just about the order we had originally powered them on. Not a fun day at all.
The fault fixed by the Dell EMC firmware concerns an Assert function which had a bad check to validate the value of a circular buffer’s index value. Instead of checking the maximum value as N, it checked for N-1. The fix corrects the assert check to use the maximum value as N.
We are serious software engineers and we have mature tools.
How can we prevent defects like this one (They are not BUGS)
With TDD, we can only write code after a failing test.
In this way, we need to think of the N scenario and explicitly check the case.
Otherwise, we cannot write code.
TDD is incredibly good for embedded systems.
Zombies is a great testing tool and also an amazing TDD companion.
The 'B' for Boundaries at zomBies tells us to explicitly check for border cases.
In this case N - 1, N, and N +1.
Whenever we use arithmetic or IF conditions, we might check what would happen if we make a mistake (like the one in this article) and change a < for a <=.
Mutation testing is a very powerful tool to check boundary scenarios.
Embedded and hardware systems are often tuned for optimal performance.
They skip some checks and are programmed with low-level languages.
Most of them avoid MAPPING the real world and use short integers as indices.
According to our MAPPER, an integer is not a shortint (or longint) and a shortint is not an integer.
Mission Critical software sometimes has recovery or fault-tolerant routines.
Following Fail Fast principle, we can anticipate disaster and let another piece of code take over instead of bricking the disks.
Systems don't fail.
We fail as software engineers and make the same mistakes over and over again.
We need to be humbler and learn from our past mistakes.
Photo by Patrick Perkins on Unsplash