
AI Coding Tip 024 - Force a Criteria Check Before the Task Ends
Don't let the AI grade its own homework.

M
I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
Search for a command to run...
Don't let the AI grade its own homework.
I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
No comments yet. Be the first to comment.
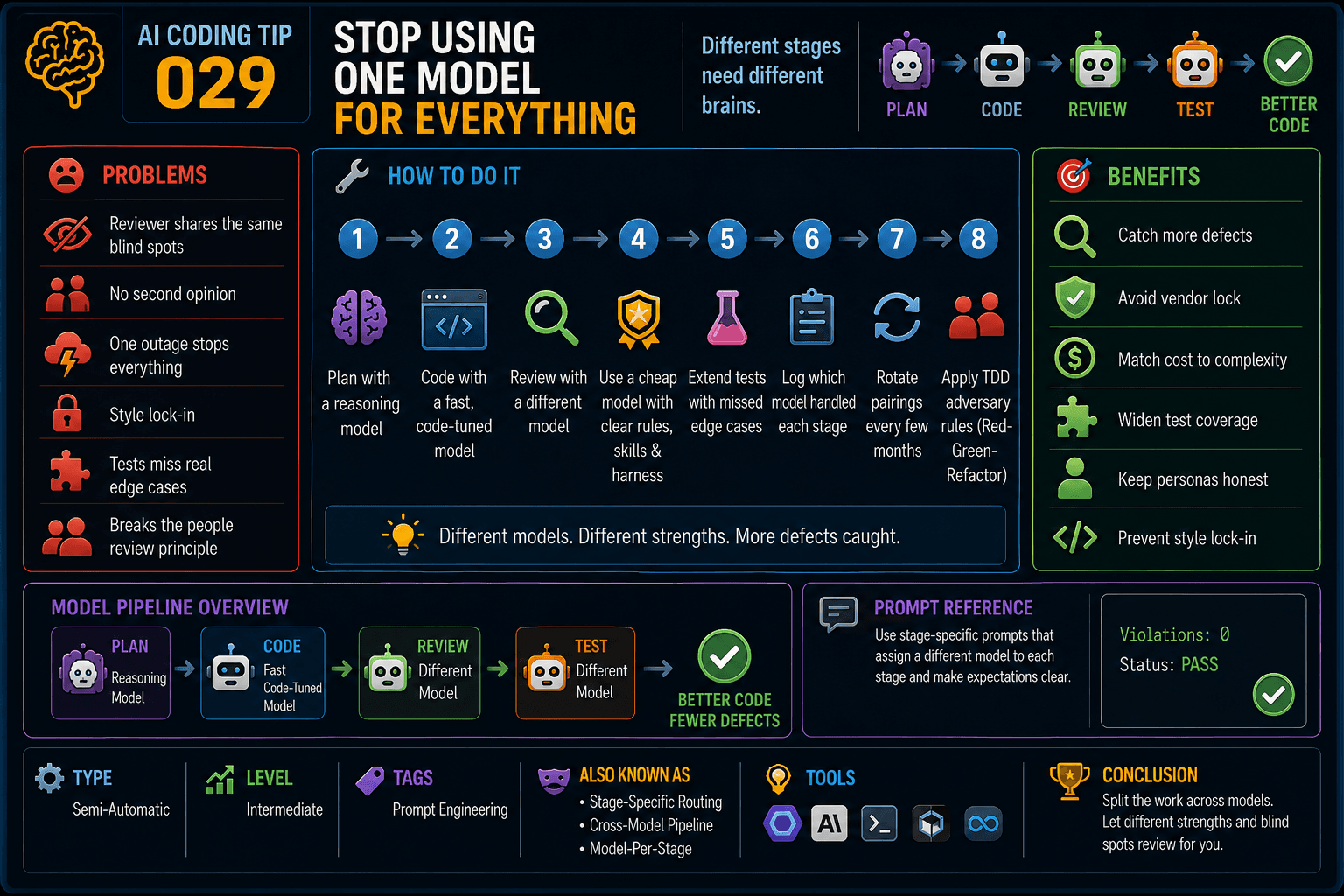
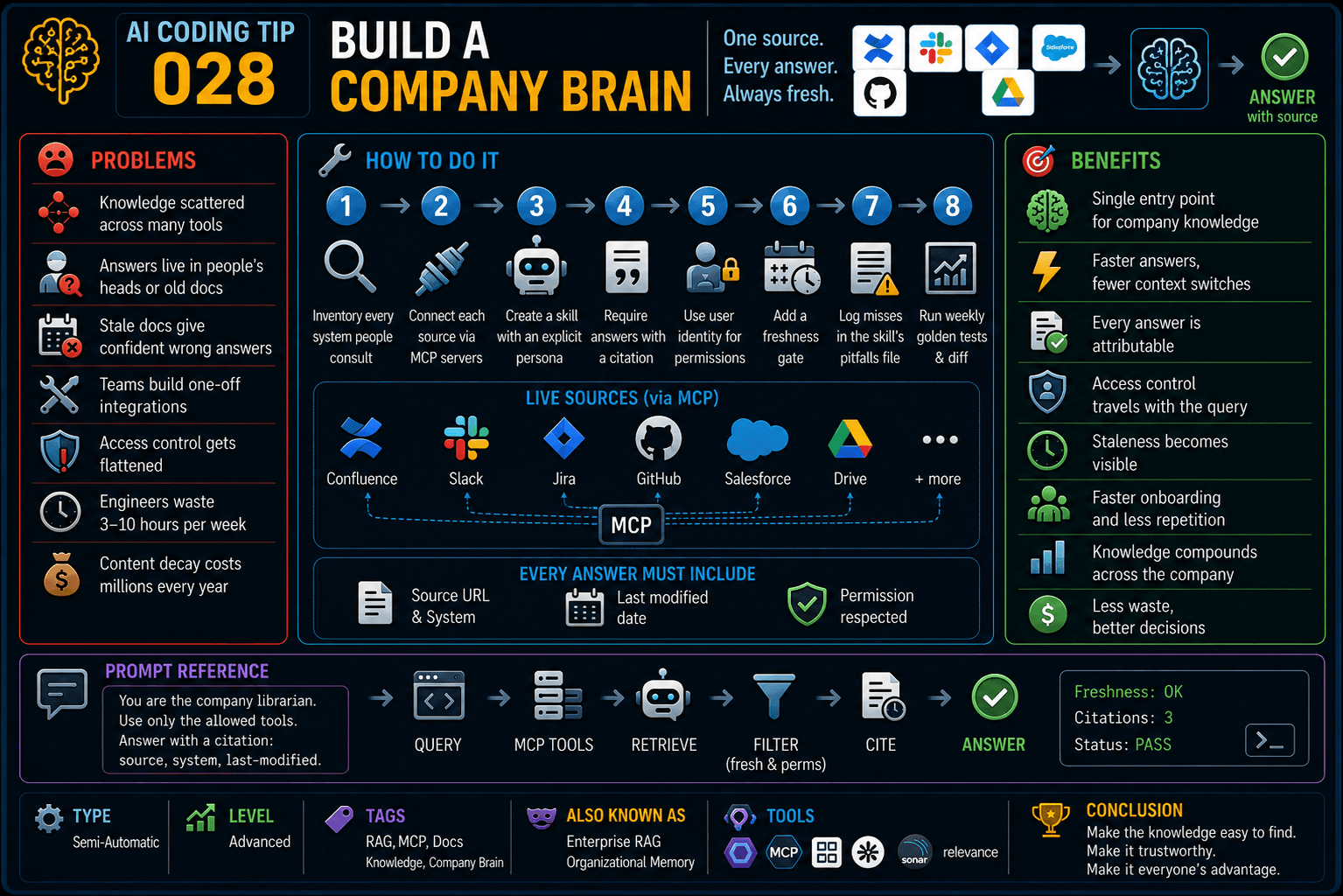
Different stages need different brains.
One Second Brain doesn't scale past one skull.
Style errors double when nobody enforces them.

Know who speaks before the skill runs TL;DR: Always define a clear role at the top of every skill file so you know whose perspective drives the execution. Common Mistake ❌ You write a skill full of

Everyone is talking about Loop Engineering. Apparently, you don't need to program anymore. TL;DR: Loop Engineering is the hottest AI workflow pattern of 2026. But it hides a dirty secret. The Tweet
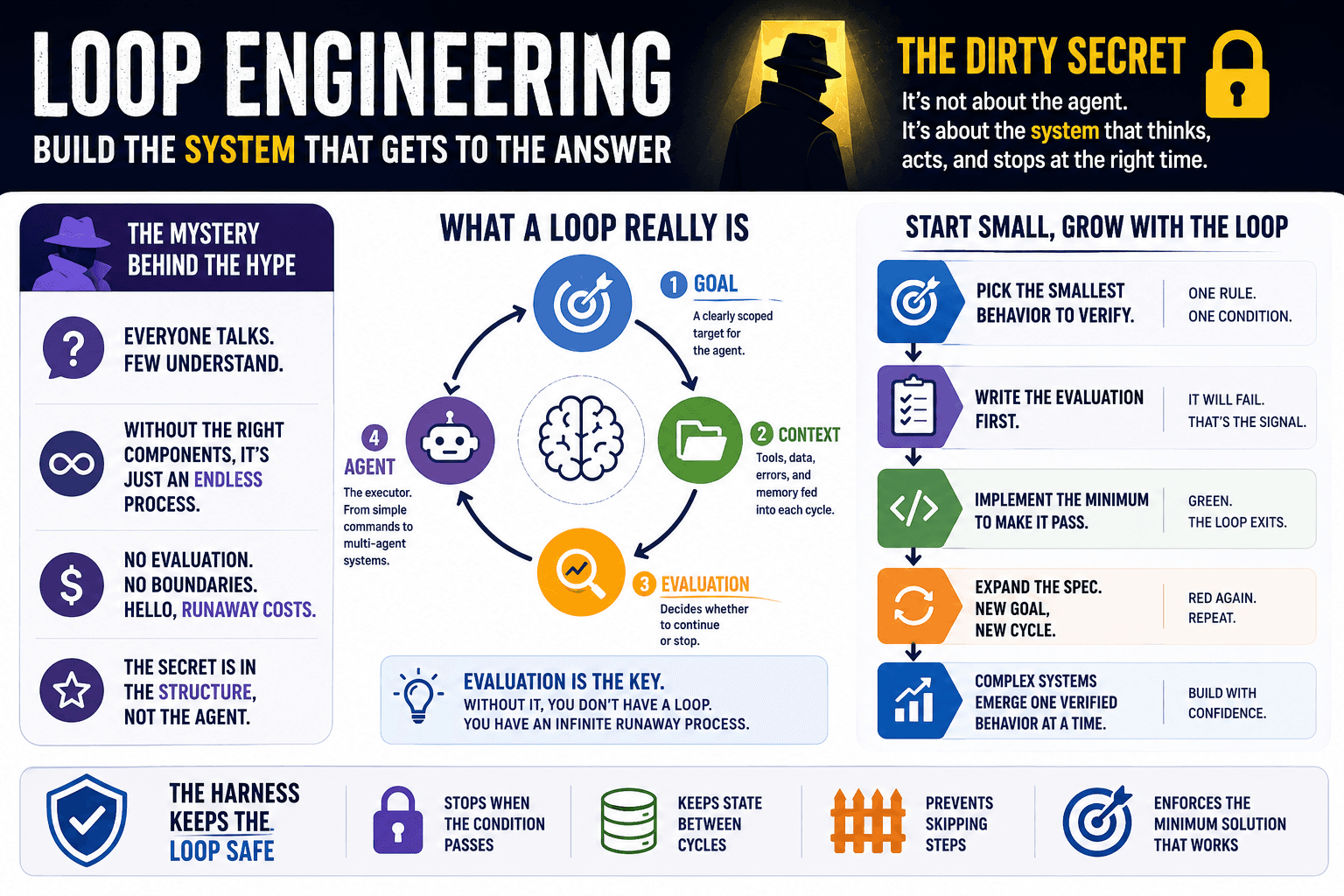
TL;DR: Spawn a fresh subagent after every task to check your rules, because the AI that did the work can't audit itself.
You write a detailed AGENTS.md with strict mandatory rules.
The AI reads the file, completes the task, and reports: "Done. I followed all the rules."
You trust the report.
It didn't check.
It assumed.
That's hallucinated compliance, and it's the default behavior of every AI agent that grades its own work.
The AI that did the work is anchored to what it intended to do, not what it actually did.
Self-reporting has no enforcement mechanism, so the agent marks PASS and moves on.
Mandatory rules in your skills get skipped silently, and the AI won't tell you it skipped them.
You discover violations after merging or deploying, not during the task.
The same context window that holds the task also holds the compliance report, which means the AI isn't truly auditing itself.
Hallucinated compliance causes real frustration when you discover violations the AI already reported as passing.
At the bottom of your AGENTS.md or skill, add an explicit instruction to spawn a verification subagent after the main task finishes.
Pass the subagent the path to every modified file and the full list of mandatory rules.
Instruct the subagent to read the files fresh and check each rule line by line.
Require the subagent to produce a checklist table with one row per rule, a PASS or FAIL status, and the exact evidence for each item.
Block task completion on any FAIL. Fix the violation before declaring done.
Restrict the subagent to read-only tools (Read, Grep, Glob) so it can't change anything while auditing.
Encapsulate the verification checklist in a dedicated validator skill so every task can reuse the same rules without duplicating them.
Independent verification: A fresh subagent has no memory of making the changes, so it audits without bias.
Forces real reading: The subagent must open the actual files and search for violations instead of assuming.
Catches hallucinated compliance: The subagent can't mark a rule PASS without showing the exact evidence it found.
Repeatable audit: You get the same check after every task without extra prompting.
Safe auditing: A read-only subagent can't accidentally modify the code it's reviewing.
Reduces frustration: You stop discovering rule violations after the task is marked done, because the subagent already caught them before you moved on.
AI models don't naturally separate "doing" from "verifying."
When you ask the same agent that built a feature to confirm it followed the rules, it re-reads its own output through the lens of what it intended to do.
Not what it actually did.
The fix is the same one used in software testing: separate the builder from the auditor.
A subagent spawned after the task finishes starts with a clean context.
It reads the skill rules fresh.
It opens the actual files instead of relying on memory.
This is why QA engineers exist.
The person who wrote the code shouldn't be the only one who tests it.
The risk of hallucinated compliance grows with task complexity.
A three-step task is easy to self-verify.
A 20-rule nested AGENTS.md with dozens of file changes isn't.
Some skills already enforce this pattern.
The ai-coding-tip-validator spawns a mandatory post-completion audit subagent after every validation session, which reads the SKILL.md files fresh and verifies each mandatory rule against the final article state.
Think of this as a harness for the AI's output.
The harness doesn't restrict what the AI can do.
It verifies the output meets your criteria before you act on it.
Refactor the SingletonController class
following all the rules in AGENTS.md.
When you're done, tell me you followed every rule.
Refactor the SingletonController following all rules in AGENTS.md.
After you finish, spawn a subagent with this task:
"Read the modified file at src/Controller.php.
Read every rule marked MANDATORY, CRITICAL, or REQUIRED
from AGENTS.md.
For each rule, verify the file directly. Don't rely on memory.
Produce a table with one row per rule:
| # | Rule | Status | Evidence |
|---|------|--------|----------|
Mark PASS with the exact line you found as proof.
Mark FAIL with the exact violation.
Only use Read, Grep, and Glob tools.
Don't change any files."
Block completion until the subagent reports all PASS.
Running a verification subagent adds one step per task.
Keep the checklist short and explicit.
Vague rules produce vague audits.
A subagent can only verify what it can read.
If your rule depends on runtime behavior, mark it as requiring manual verification.
Don't use the audit subagent as a substitute for well-written rules.
Fix broken rules in AGENTS.md instead of patching them at audit time.
Pair this pattern with small, focused tasks.
A 3-file change is much easier to audit accurately than a 20-file change.
[X] Semi-Automatic
This pattern requires an AI with agentic capabilities that can spawn subagents.
Tools that support it include Claude Code, Cursor, Devin, and GitHub Copilot Workspace.
Standard chat interfaces (ChatGPT, Claude.ai in non-agent mode) can't use this pattern.
A subagent audit only covers what the rules explicitly state.
Implicit expectations don't appear in the checklist.
A complex AGENTS.md with 50+ rules may cause the subagent to hit context limits.
Break large rule files into smaller focused files.
This pattern adds latency.
On time-sensitive tasks, you may choose to audit only the rules that are hardest to self-verify.
[X] Intermediate
https://maximilianocontieri.com/ai-coding-tip-003-force-read-only-planning
https://maximilianocontieri.com/ai-coding-tip-004-use-modular-skills
https://maximilianocontieri.com/ai-coding-tip-005-keep-context-fresh
https://maximilianocontieri.com/ai-coding-tip-006-review-every-line-before-commit
https://maximilianocontieri.com/ai-coding-tip-014-use-nested-agents-md-files
https://maximilianocontieri.com/ai-coding-tip-015-force-the-ai-to-obey-you
https://maximilianocontieri.com/ai-coding-tip-022-give-ai-a-harness-to-work-with
The AI that did the work is the worst candidate to verify it followed the rules.
Spawn a fresh subagent after every task.
Give it the checklist and the output files.
Make it read the files, not its memory.
PASS or FAIL. No self-reporting.
Lost in the Middle: How Language Models Use Long Contexts
Effective Context Engineering for AI Agents
Claude Prompt Engineering Best Practices
OpenAI Best Practices for Prompt Engineering
The views expressed here are my own.
I am a human who writes as best as possible for other humans.
I use AI proofreading tools to improve some texts.
I welcome constructive criticism and dialogue.
I shape these insights through 30 years in the software industry, 25 years of teaching, and writing over 500 articles and a book.
This article is part of the AI Coding Tip series.