The Dirty Secret Behind Loop Engineering
I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
Everyone is talking about Loop Engineering. Apparently, you don't need to program anymore.
TL;DR: Loop Engineering is the hottest AI workflow pattern of 2026. But it hides a dirty secret.
The Tweet That Started It All
https://x.com/steipete/status/2063697162748260627
In June 2026, Addy Osmani and the PostHog team published their takes on the same idea.
Instead of prompting an AI agent manually, you build the system that prompts the agent for you.
The metaprompt idea has a fancy name now. Loop Engineering.
Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead. Addy Osmani
PostHog ran it in production. The result: an 11% performance improvement and a 3-year-old defect fixed in the query engine, hands-off.
The internet got excited. Again. Rightly so.
But there's a dirty secret hiding behind the vocabulary.
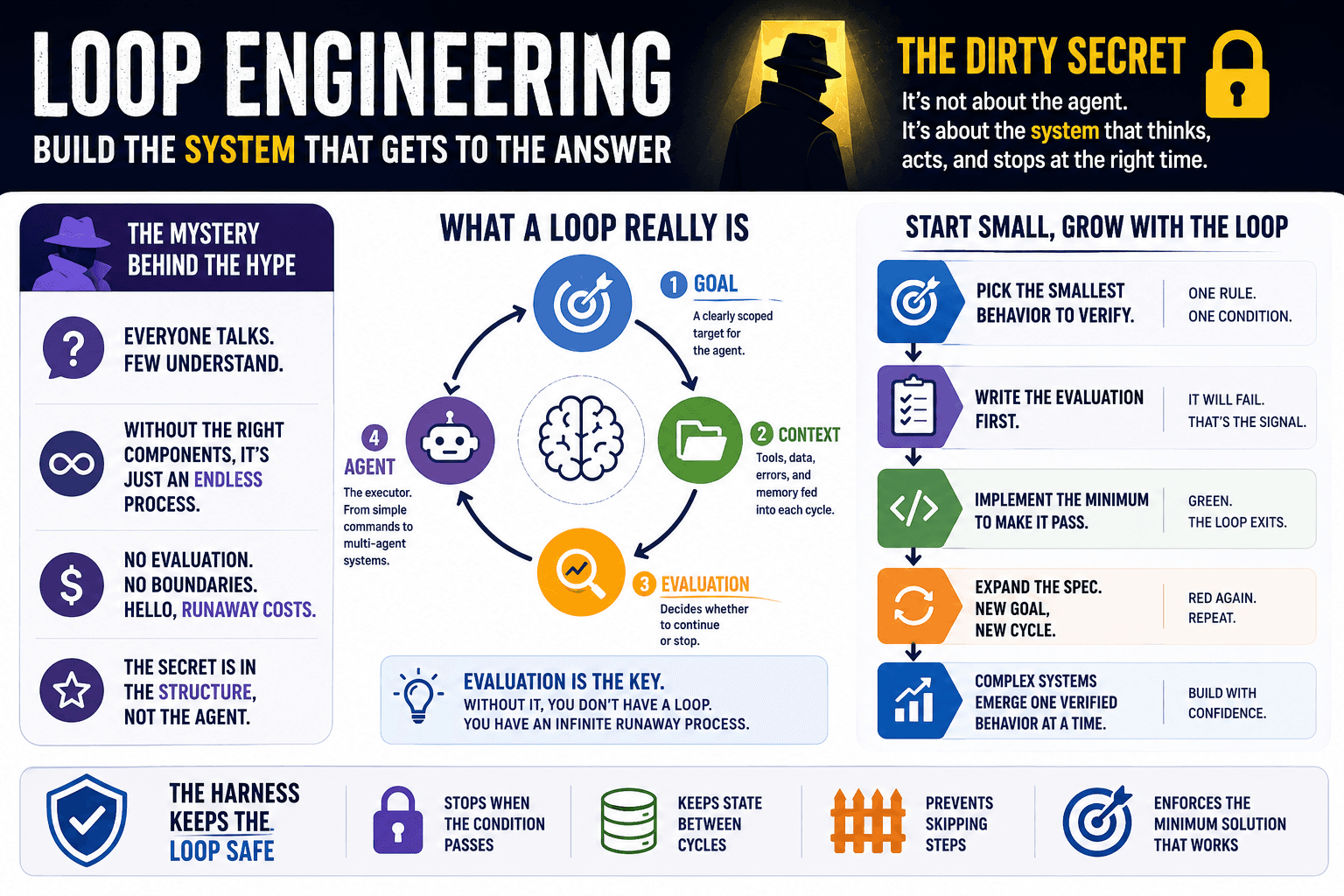
What a Loop Actually Is
A functional loop has four parts:
- Goal: a clearly scoped target for the agent
- Context: tools, data, errors, and memory fed into each cycle
- Evaluation: the mechanism that decides whether the loop should continue or stop (a.k.a. the exit criteria)
- Agent: the executor, from a simple
/goalcommand to a full multi-agent harness
The evaluation component is the key. Without it, you don't have a loop. You have an infinite runaway process. Good luck with your token bill!
You also need a harness: the scaffolding that contains the agent, enforces your rules, and gives the loop a safe boundary to operate within.
Start With the Smallest Possible Spec
Here's where Loop Engineering gets interesting, and where most people get it wrong.
If you write an enormous spec covering all possible cases before the loop runs once, you aren't doing Loop Engineering. You're doing waterfall with extra steps.
Think about what you want to verify. Not the whole system. One behavior.
Let's build a FIFA World Cup 2026 group standings simulator using Loop Engineering.
Germany, Ivory Coast, Ecuador, and Curaçao in Group E. Three rounds of matches. The top two advance, and the best third-place teams also qualify.
What's the smallest possible spec?
A team that wins a match gets 3 points.
That's it. Not the whole group. Not the knockout bracket. One rule about one match.
This is the Spec-Driven approach: you define intent before implementation, but you keep the scope surgical.
Loop Iteration 1: Write a Spec That Fails
Here's your first loop cycle. You define the evaluation condition before any implementation exists.
def test_win_gives_three_points():
germany = Team("Germany 🇩🇪")
curacao = Team("Curaçao 🇨🇼")
match = Match(germany, curacao, home_goals=7, away_goals=1)
standings = GroupStandings()
standings.record(match)
assert standings.points_for(germany) == 3
assert standings.points_for(curacao) == 0
Run this. It fails. Team doesn't exist. Match doesn't exist. GroupStandings doesn't exist.
(Germany beat Curaçao 7-1 on June 14, 2026. The spec matches reality.)
The loop condition is red 🔴.
This is the signal the loop needs. The evaluation says: not done yet. Keep running until you achieve the /goal.
Loop Iteration 2: Make the Evaluation Pass
Now you give the agent the minimal implementation to make the loop exit:
class Team:
def __init__(self, name):
self.name = name
class Match:
def __init__(self, home, away, home_goals, away_goals):
self.home = home
self.away = away
self.home_goals = home_goals
self.away_goals = away_goals
class GroupStandings:
def __init__(self):
self._points = {}
def record(self, match):
if match.home_goals > match.away_goals:
self._points[match.home] =
self._points.get(match.home, 0) + 3
self._points[match.away] =
self._points.get(match.away, 0)
elif match.away_goals > match.home_goals:
self._points[match.away] =
self._points.get(match.away, 0) + 3
self._points[match.home] =
self._points.get(match.home, 0)
def points_for(self, team):
return self._points.get(team, 0)
Run the spec. Green 🟢. Loop exits.
Not because you modeled every rule. Because you satisfied the single condition the loop was checking.
Loop Iteration 3: Expand the Spec, Red 🔴 Again
The loop restarts with a new goal:
def test_draw_gives_one_point_each():
ecuador = Team("Ecuador 🇪🇨")
curacao = Team("Curaçao 🇨🇼")
match = Match(ecuador, curacao, home_goals=0, away_goals=0)
standings = GroupStandings()
standings.record(match)
assert standings.points_for(ecuador) == 1
assert standings.points_for(curacao) == 1
Red 🔴. The record method doesn't handle draws.
(Ecuador drew 0-0 with Curaçao on June 20. Again, the spec matches reality.)
The evaluation fails. Loop continues. Add the draw case. Green 🟢. Loop exits.
Growing the Loop: Group Stage Completion
Cycle by cycle, the spec expands:
- Iteration 4: Multiple matches accumulate points correctly across all three rounds
- Iteration 5: Teams with equal points get ranked by goal difference
- Iteration 6: Ties in goal difference break by goals scored
- Iteration 7: Top 2 teams advance to the knockout stage
Each iteration follows the same pattern: write the evaluation condition first, run it (it fails), implement the minimum to pass, run again (green 🟢), move to the next cycle.
After 7 iterations, Group E final standings:
Group E - Final Standings
1. Germany 6 pts GD: +6 GF: 10
2. Ivory Coast 6 pts GD: +2 GF: 4
3. Ecuador 4 pts GD: 0 GF: 2
4. Curaçao 1 pt GD: -8 GF: 1
Growing the Loop: Knockout Brackets
The same loop discipline applies to bracket generation.
def test_group_winner_faces_different_group_runner_up():
bracket = KnockoutBracket(completed_group_results)
round_of_32 = bracket.round_of_32()
assert round_of_32[0].home == group_e_standings.first_place()
assert round_of_32[0].away == group_f_standings.second_place()
Red 🔴 first. Then green 🟢. Then the next spec.
The loop doesn't know the full bracket before it starts. It discovers the bracket one evaluation at a time.
What Keeps the Loop Safe: The Harness
None of this works without a structure that:
- Runs the evaluation on every cycle
- Stops the agent when the condition passes
- Prevents the agent from moving to the next spec until the current one is green 🟢
- Stores state between cycles so the next spec knows what already passed
- Forces the minimum solution that makes the evaluation pass, nothing more.
- Over-engineering is structurally impossible when the loop stops the moment the spec is green 🟢
That is the harness. The harness is what separates Loop Engineering from running Claude in a while True loop and hoping for the best.
Codex and Claude Code now ship with built-in loop infrastructure: /goal, /loop, isolation: worktree, and sub-agents for separate verification.
The harness is no longer something you build from scratch.
The agent that verifies runs in a clean sub-agent with no memory of what the implementer did.
It is an independent inspector seeking Judgment Day moments.
It can't grade its own work because it never saw the work being done.
This is the same reason you don't ask a developer to review their own pull request.
The Numbers That Made Everyone Pay Attention
Why is this getting attention now and not five years ago?
Because the evaluation step (the part where the loop decides whether to continue) used to require a human. Now it doesn't.
- Opus 4.8 completes 50% of tasks requiring 12 hours of work, at 6x the speed of its predecessor one year ago
- Stripe migrated an entire codebase in one day that would have taken a team two months manually
- PostHog's autoresearcher loop delivered 11% performance gains and fixed a three-year-old defect, unsupervised
When models were weaker, the loop needed you to interpret the evaluation output. Now the evaluation can be the test suite itself, and the agent reads it directly.
The Dirty Secret
You've been reading about Test-Driven Development.
The spec is the test.
The evaluation is the test runner.
The loop is the red 🔴-green 🟢-refactor 🔵 cycle.
The goal is the failing assertion.
Loop exits when evaluation passes means the test is green 🟢.
Kent Beck described this in 2003.
Ward Cunningham was doing it before that.
There's even a structured guide for choosing which goal to tackle next: the ZOMBIES framework. Zero, One, Many, Boundary, Interface, Exceptional, Simple. That is your loop iteration order.
What changed isn't the technique. What changed is who runs the loop.
In 2003, the human developer wrote the test, ran it, read the red 🔴 output, wrote the minimum code, ran it again, saw green 🟢, and moved to the next test.
That was the loop.
In 2026, the functional developer writes the spec, the agent runs the cycle, reads the red 🔴 output, writes the minimum code, runs the cycle again, sees green 🟢, and starts the next spec. That's still the loop.
The red 🔴-green 🟢-refactor 🔵 vocabulary wasn't memorable enough for 2026. So the industry renamed it.
The evaluation is still the test. The cycle is still TDD. The discipline is exactly the same.
Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go. Addy Osmani
Kent Beck said the same thing. He just called it something else.
A few extra tips:
- Before the first iteration, plan in read-only mode: decide which specs to write in which order. No code yet.
- Force the Agent to always write a failing test with the steps to repro of a defect or the missing functionality, and force a criterion check before it marks the task done.
- Watch the whole process, don't ship it to production without your explicit approval.
- You need to understand all the solution code. The loop runs fast. Don't let it outrun your understanding. Passive automation creates comprehension debt.
- Configure the harness to commit automatically every time the tests pass. This is TCR (Test && Commit || Revert): if green 🟢, commit; if red 🔴, revert. Each passing cycle leaves a clean checkpoint. The loop never drifts into an invalid state.
- One spec per cycle means one small pull request per feature. Reviewers read diffs, not novels.
- TDD has three steps, not two. Red 🔴, green 🟢, refactor 🔵. The loop handles the first two automatically. The third one still needs you. A harness with coupling and cohesion metrics tells you when the code that just turned green 🟢 is worth keeping as-is. High coupling or low cohesion after a passing cycle is the signal to refactor before moving to the next spec.
Loop Engineering on Legacy Systems
Loop Engineering isn't only for greenfield code or fancy MVPs. It's also how you safely modernize systems that have no tests at all.
The trick is the same: write the spec first.
On a legacy system, that spec describes behavior the system already has.
You're not inventing new rules. You're pinning existing ones so the loop can't break them.
Harnesses are even more critical on production legacy systems.
The loop then shrinks the untested surface one cycle at a time.
Each green 🟢 spec is a behavior the agent can't accidentally destroy in the next iteration. Squeezing TDD onto legacy systems works the same way whether a human runs the cycle or an agent does. The discipline is identical. What changes is the speed.
What are you waiting for? Build your harnesses. Start your loops.