Coupling: The one and only software design problem
A root cause analysis of all failures of our software will find a single culprit with multiple costumes.

I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
The enemy is always there. Many times disguised as laziness, sometimes simplification, and usually with the optimization outfit.
We will always find a single culprit if we analyze many common mistakes. The bloody coupling.
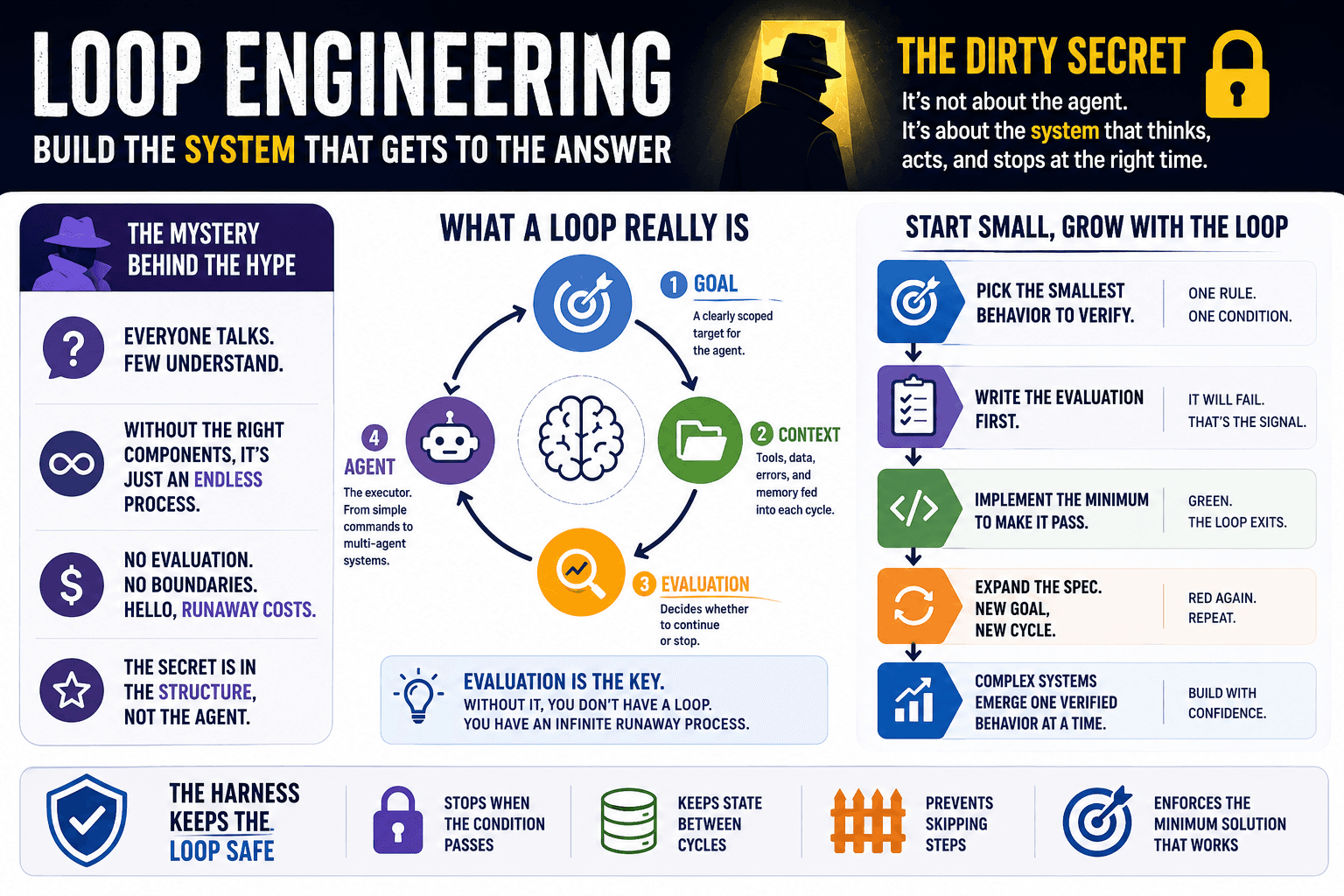
Expanding the axioms
In previous articles, we talked about the definition of software design in an axiomatic way. We enunciated the rule to know what objects to represent in our model:
and we showed the only principle that we should use:
We are going to add the only mistake we should avoid by all means to this axiomatic list.
Coupling Examples
Classes
Global variables link a global reference from the code. This link cannot be easily broken unless we connect to interfaces instead of references and use dependency inversion (the SOLID D). Having global variables in a structured language involves being attached to a reference that cannot be replaced, mocked, or deferred over time. In object-oriented programming using classification languages, the problem is the same.
This is a step back to more pure functional languages where there's an explicit prohibition enforced by preventing functions from having side effects.
If we take an extreme and minimalist position:
Every function/method should only invoke objects in their attributes and/or their parameters.
Settings
Those plugs that allow us to 'configure' the software using arbitrary global references from anywhere on the code.
They are a particular case of global references and prevent the correct unit test of a system. If something must be configurable, this possible configuration must be passed as an object as we proposed in this article.
In this way, we can replace the configuration on tests and have full control and no side effects.
Hidden Assumptions
As we have described in the note on bijections, partially ignoring this principle implies running the risk of losing information on the contract and making mistakes under different interpretations.
In our previous example where we represented 10 meters with the number 10.
In this case, we are coupled with the hidden assumption that 10 represents 10 meters.

Hidden assumptions appear at the worst moments of the development cycle.
Null References
This is a particular case of the item above. Null should never be used because it violates our only non-negotiable principle since it is not bijective with any real-world entity (Null only exists in the world of developers).
If we decide to use a null as a flag of some particular behavior we are coupling the decision of the function implementer to the one who invokes it. This ambiguous semantics brings countless problems.
The same issue happens when someone sets a property to null coupling to the reader of the attribute.
Singletons
The Singleton pattern is a controversial design pattern. If we look at it under the guidance of our single design rule we will discard its use immediately. An object is represented by a Singleton if there is only one instance of its class. This also violates the principle of being declarative since the uniqueness of a concept, in general, is coupled to implementation problems, so we are violating the only design rule that we imposed ourselves.
Besides, singletons are generally referenced through their class name, so we add all the problems mentioned in the first paragraph.
If/Case/Switch and all their friends
If clauses have a hidden coupling between the condition and the place where they are evaluated and violate the open/closed principle. (The O on the solid acronym).
Ifs (and hence cases) should be avoided unless these conditions are business rules thus related to the bijection.
A business rule 'A bonus should be paid to employees with 3 or more years at a company' can be safely stated by an If clause but rules such as 'If the employee's position is junior then pay them 10.000' shouldn't since this is not essential on the business rule but accidental therefore should be treated with polymorphism.
In the real world, employees are aware of their position, but they are not usually aware of their age in the company.
Documentation
If you need to add comments to your code there's a smell you might not be declarative enough.
Code documentation is many times not synced with the code itself. Many times developers change the code and don't have enough courage to change the code documentation bound to the code. This is another subtle coupling case.
Some months later we read the code and the documentation and need a lot of time to figure out their meaning.
Ripple effect
If we are faithful to our unique design rule and have a declarative model, we will expect, consequently, that a small change in the requirements will generate a small change in the model and so on. When this does not occur, the dreaded ripple effect is produced, turning the software unpredictable and full of potential errors that hinder its maintenance.

Solutions
There are many ways to remove coupling once identified.
In this article we will see coupling reduction techniques:
Conclusions
Coupling is necessary because the objects must know each other to collaborate and be able to solve the problems raised in the simulation.
Finding out which binding is good versus which one is bad to avoid the wave effect requires a little experience and a lot of staying true to the rules defined in this article.
Part of the objective of this series of articles is to generate spaces for debate and discussion on software design.
We look forward to comments and suggestions on this article.
This article is published at the same time in Spanish here