Code Smell 317 - Email Handling Vulnerabilities
Your system trusts UI input and sends security emails to attacker-controlled addresses instead of database values

I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
TL;DR: You normalize email for lookup but trust UI data for delivery, breaking identity ownership.
Problems 😔
- UI trust
- Identity drift
- Unicode confusion
- String identity
- Boundary breach
- Collation confusion
- Security bypass
- Account takeover
- Email spoofing
Solutions 😃
- Server owns identity
- Never trust UI input
- Use strict collation
- Use canonical emails
- Normalize once
- Persist then act
- Implement Multi-Factor Authentication
Refactorings ⚙️
Context 💬
When you handle user input containing Unicode characters, system components interpret them in many differnet ways.
Some database engines with certain collations (like utf8mb4_unicode_ci) treat Unicode characters with diacritics as equal to their ASCII counterparts.
For example, 'à' equals 'a'.
However, email servers, programming languages, and other systems distinguish between these characters.
This inconsistency creates a dangerous security vulnerability.
An attacker can set up an email account named attacker@gmàil.com (with Unicode 'à').
Then the attacker requests a password reset for the victim's legitimate account victim@gmail.com (ASCII 'a'), filling the email victim@gmàil.com.
Your database collation finds a match because it treats both addresses as equal.
However, you commit the critical mistake of using the untrusted UI input to send the reset email instead of using the email address stored in your database.
The reset link goes to the attacker's Unicode address, giving them complete control of the victim's account.
You violate the fundamental security principle: never trust data from the UI.
You must always use the canonical values from your database for security-critical operations.
Sample Code 📖
Wrong ❌
def reset_password(email_from_ui):
# email_from_ui = "victim@gmàil.com"
# (attacker's Unicode address from UI)
# Database with utf8mb4_unicode_ci collation
# treats 'à' = 'a', so this query finds:
# victim@gmail.com stored in the database
cursor.execute(
"SELECT * FROM users WHERE email = %s",
(email_from_ui,)
)
user = cursor.fetchone()
if user:
# CRITICAL MISTAKE: Trusting UI data
# Sends email to the attacker's Unicode address
# instead of using user['email'] from DB
send_reset_email(email_from_ui)
# Should use: send_reset_email(user['email'])
return True
return False
# Attack scenario:
# DB stores: victim@gmail.com (ASCII, legitimate)
# Attacker controls: attacker@gmàil.com (Unicode)
# Attacker requests reset with: victim@gmàil.com
# Collation matches the victim's account
# Email sent to: victim@gmàil.com (attacker's address!)
Right 👉
import unicodedata
def normalize_email(email):
# Convert to NFKC normalized form
normalized = unicodedata.normalize('NFKC', email)
# Ensure only ASCII characters
try:
normalized.encode('ascii')
except UnicodeEncodeError:
raise ValueError(
"Email contains non-ASCII characters."
)
return normalized.lower()
def reset_password(email_from_ui):
# DEFENSE 1: Normalize and validate input
try:
normalized_email = normalize_email(email_from_ui)
except ValueError:
# Reject non-ASCII emails immediately
return False
cursor.execute(
"SELECT * FROM users WHERE email = %s",
(normalized_email,)
)
user = cursor.fetchone()
if user:
# DEFENSE 2: NEVER trust UI data
# Always use the canonical email from the database
database_email = user['email']
send_reset_email(database_email)
# NOT: send_reset_email(email_from_ui)
# NOT: send_reset_email(normalized_email)
return True
return False
# Now the attack fails:
# Attacker sends: victim@gmàil.com
# Normalized to: rejected (non-ASCII)
# Even if it passed, email sent to: user['email']
# (the actual stored value, not the attacker's input)
Detection 🔍
[X] Semi-Automatic
You can spot this smell with static analyzers that check for inconsistent string handling.
Run Unicode fuzzers to test inputs.
Review the code for places where you use raw UI data in sensitive operations like emails.
Check how you handle user input, especially authentication and email validation.
Look for the critical pattern: using UI-provided data directly in external communications instead of database values.
Search for send_email(user_input) patterns where you should use send_email(db_record['email']).
Check your database collation settings and ensure you apply Unicode normalization consistently.
Flag any code that uses the original user input after a successful database lookup - this is the core vulnerability.
Static analysis tools can flag when you use UI input without normalization or when you bypass database values in favor of user-provided strings.
Tags 🏷️
- Security
Level 🔋
[X] Advanced
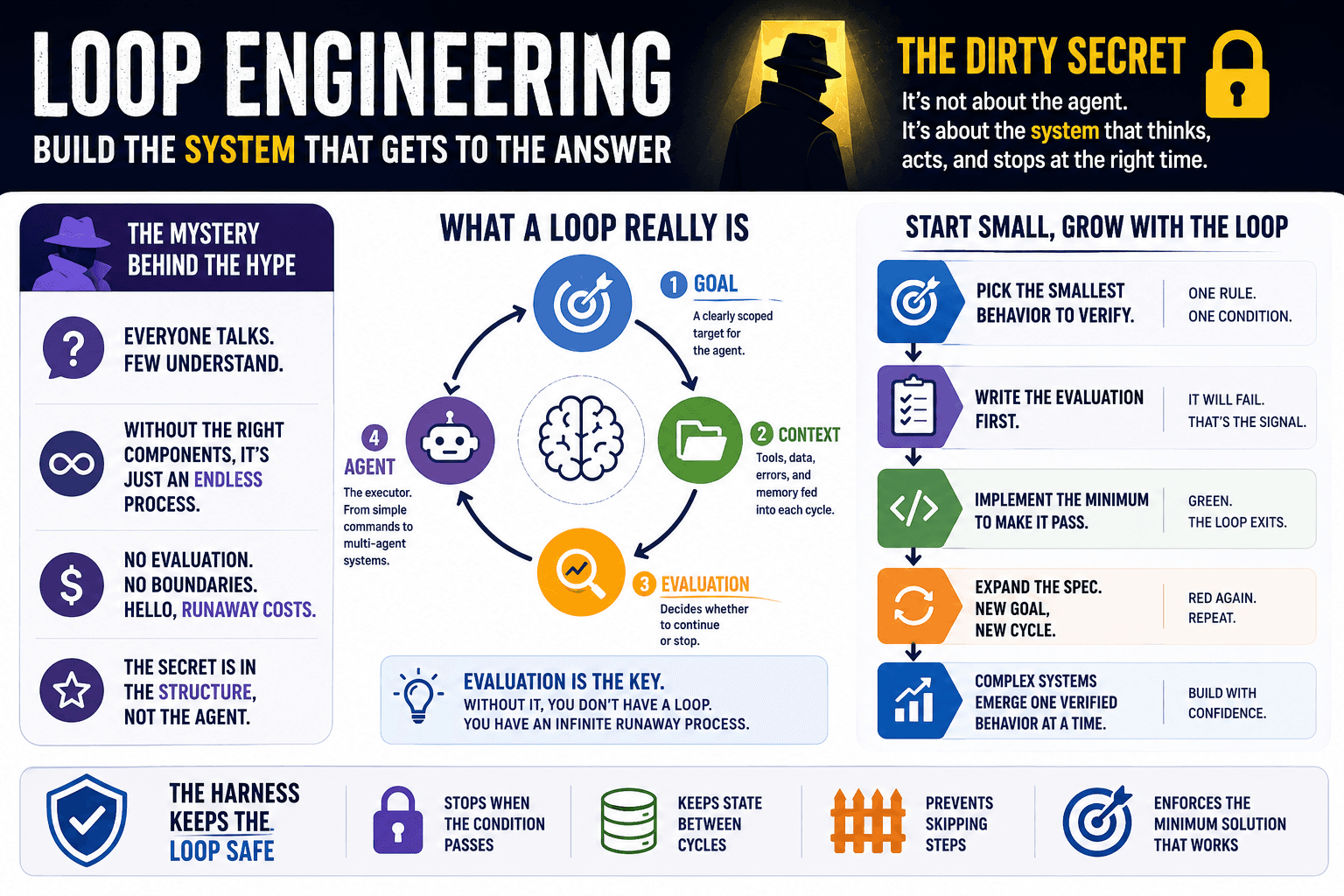
Why the Bijection Is Important 🗺️
You need a clear bijection between real-world email addresses and your system's representation.
String representation is always an accidental problem unrelated to the real world.
When you allow Unicode characters without proper normalization, you break this mapping.
The MAPPER sees one email address, but your database collation creates multiple representations that map to the same stored value.
This breaks the essential property that each real-world email address corresponds to exactly one account. An attacker exploits this broken bijection by creating a Unicode variant that your database treats as equivalent to an existing ASCII address, while email servers treat them as distinct destinations.
AI Generation 🤖
AI tools sometimes generate this smell because they are pre-trained with poor code examples, and they focus on basic logic without considering encoding edge cases.
AI Detection 🧲
AI can fix this smell if you give clear prompts about normalization, security vulnerabilities, and stored data usage.
Try Them! 🛠
Remember: AI Assistants make lots of mistakes
Suggested Prompt: Model email as a server-owned value object.Normalize once.After database lookup,discard UI input for security actions.
| Without Proper Instructions | With Specific Instructions |
| ChatGPT | ChatGPT |
| Claude | Claude |
| Perplexity | Perplexity |
| Copilot | Copilot |
| You | You |
| Gemini | Gemini |
| DeepSeek | DeepSeek |
| Meta AI | Meta AI |
| Grok | Grok |
| Qwen | Qwen |
Conclusion 🏁
Unicode normalization inconsistencies combined with trusting UI input create critical security vulnerabilities.
You must never use untrusted UI data for security-critical operations like sending password reset emails.
Always normalize all user input to a canonical form and validate it strictly. Most importantly, always use the canonical values from your database, not the user-provided input, when performing authentication or sending security-related communications.
The safest approach restricts email addresses to ASCII-only characters and always treats the database as the single source of truth
Relations 👩❤️💋👨
More Information 📕
Disclaimer 📘
Code Smells are my opinion.
Credits 🙏
Photo by Aurèle Castellane on Unsplash
Never trust input you do not control.
Bruce Schneier
This article is part of the CodeSmell Series.