How to Decouple a Legacy System

I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
An exercise improving legacy code
There are many articles explaining how to make a good design and what rules to follow. In this note we will see a concrete example on how to convert a legacy design into a better one.
The problem
Many existing systems have coupling problems. Therefore, their maintainability is reduced. Making a change in this type of system brings a large ripple effect.
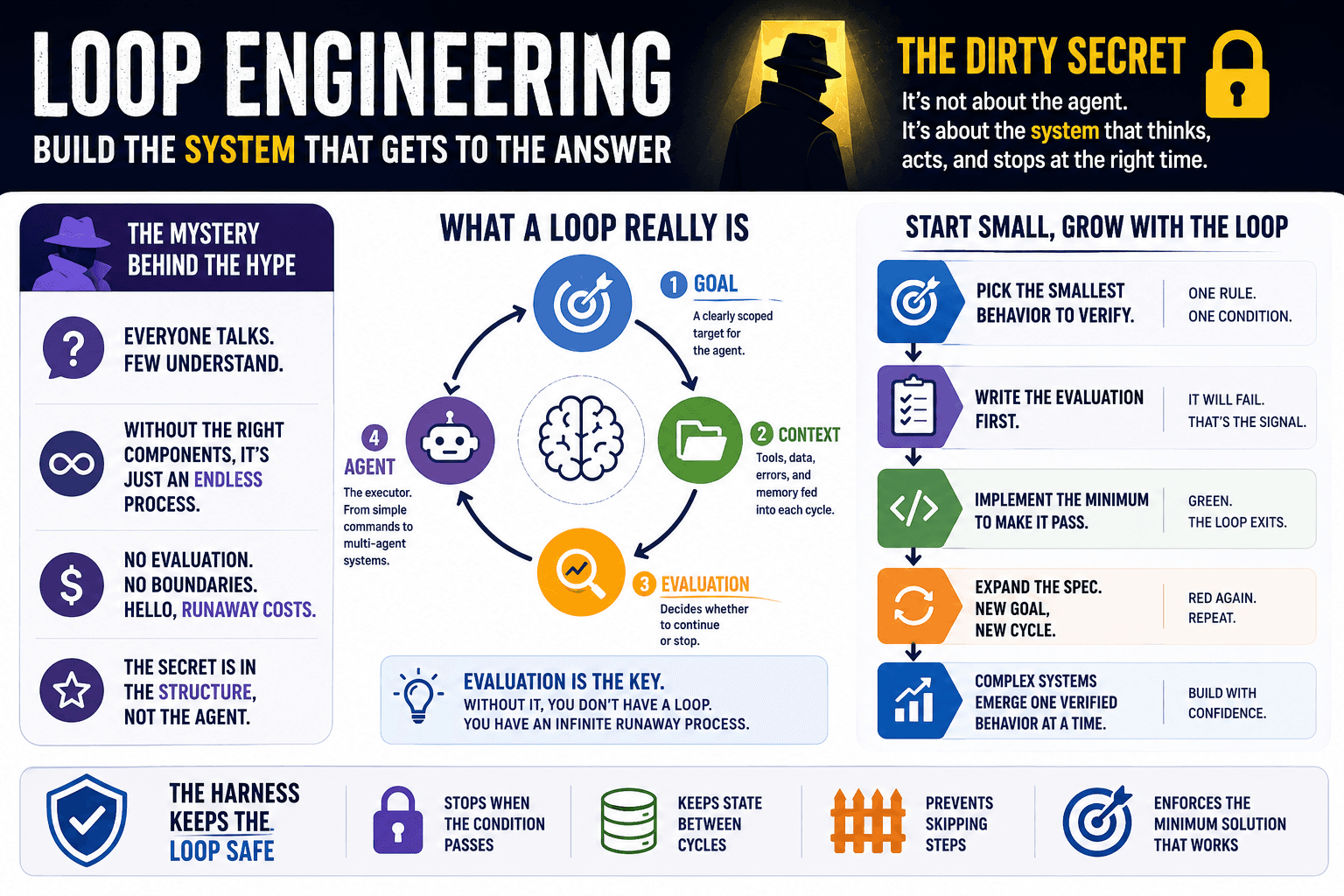
Let’s assume we have an existing process.
The system applies various algorithms to deduce the hyper-parameters) of a supervised learning model.
A new requirement is requested:
To be able to see, in production, data on the performance of each strategy in real time.
Decoupling the system
Let’s see the process entry point:
… the supervised learning class:
and the method invoked:
In the case of a productive system, the first thing we must do is identify its current coverage. The system has a series of automated unit and functional tests.
To measure coverage we will use the Mutation testing technique.
Unfortunately just a single test fails, so we discovered that the process is not covered and we see that the Michael Feathers maxim is sadly applied:
“An inherited system is one that has no tests”
The strategy to refactor an inherited system is to cover the existing functionality before making any changes.
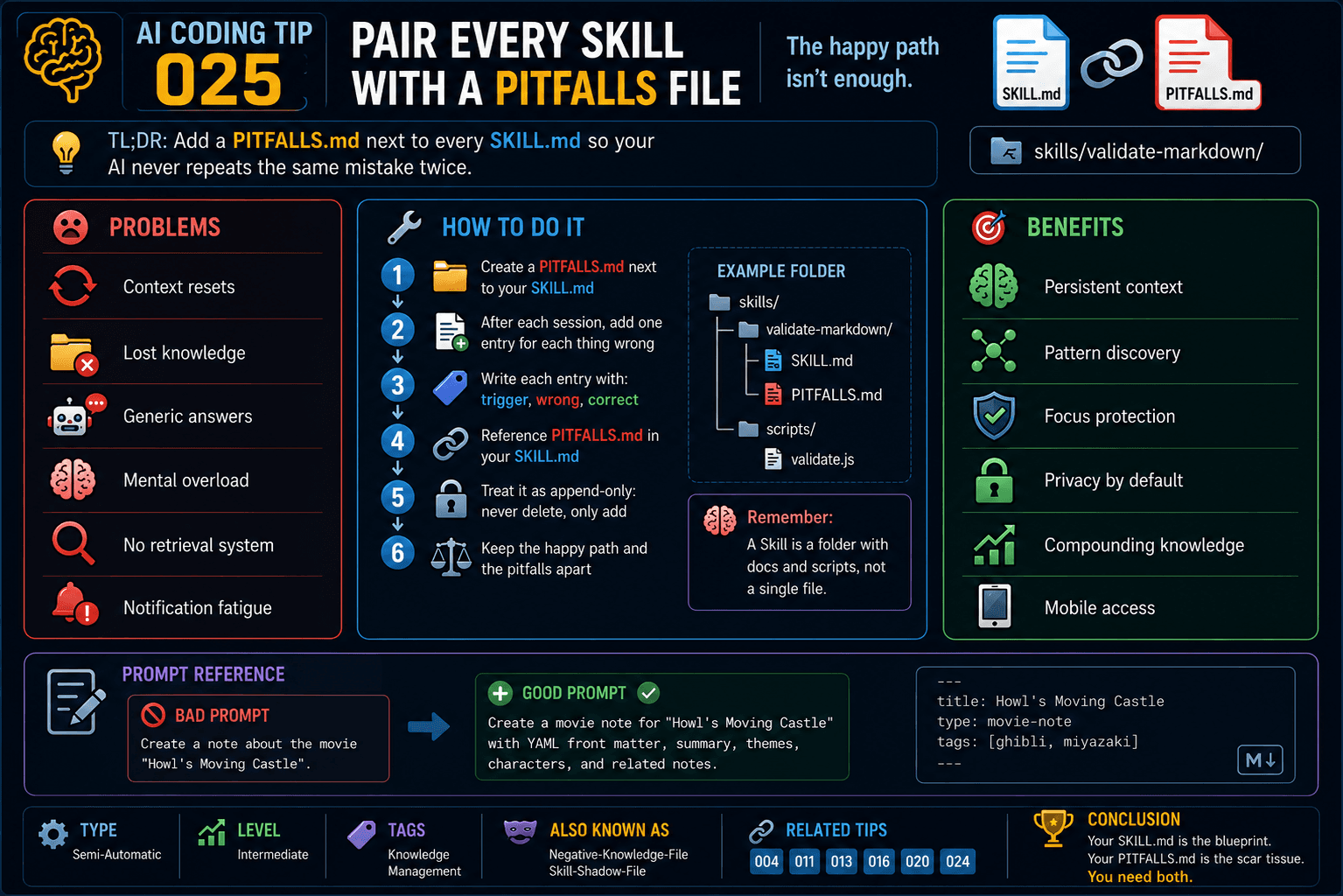
1 — Creating deferred tests.
Writing tests reveals good design interfaces among objects. Due to the current solution and the coupling it has incorporated, it is very difficult to write tests.
However, we cannot refactor to write the tests without writing the tests previously. It seems that we are facing a vicious circle.

Photo by Justin Chen on Unsplash
The possible solution to this deadlock is to write the tests declaratively, thus generating better interfaces.
We will run them manually until the coupling is resolved.
2 — We write tests to cover pre-existing functionality.
Tests can be written with a tool from the xUnit family with a false assertion (they always fail).
After having covered (for now manually) the necessary cases we can start with the refactor.
3 — The class name does not represent a real name in the bijection.
Helpers do not exist in the real world, nor should they exist in any computable model.
Let’s think about the responsibilities to choose the name in MAPPER.
For now the name is good enough, and it gives us an idea of the responsibilities of your instances in the real world.
4 — The class is a singleton.
There are no valid reasons to use singletons. This fact, in addition to generating all the problems described here:
yields a very implemental invocation (coupled to getInstance()) and not very declarative...
which we will change to:
leaving the class definition as follows:
An important design rule is:
Do not subclass concrete classes.
If the language allows this, we explicitly declare it:
5 — The same parameter in all methods.
The object is created and then it gets a magic parameter setting the identifier of the process to be optimized. This argument travels by all methods.
This is a code smell suggesting us to check the cohesion between this parameter and the process.
Looking at bijection we conclude there can be no algorithm without a process. We don’t want to have a class with setters to mutate it:
Therefore we will pass all the essential attributes during construction.
The way to know if an attribute is essential is to take away all the responsibilities associated with that object. If it can no longer carry out its responsibilities, it is because the attribute belongs to the minimal attribute set.
In this way, the strategy is immutable in its essence, with all the benefits it brings us.
6 — We find a design pattern.
The process, according to bijection, models a real world process. This seems to fit the Commandpattern.
However, we believe that it is closer to a method object where there is an ordered sequence of executions, modeling the different steps of an algorithm.
7 — Interchangeable behavior resembles yet another pattern.
As the name we assigned to the object according to its responsibilities suggests, this process models an execution strategy that will compete with other polymorphic strategies.
This is the intention of the Strategy pattern.
Names should match the observed responsibilities.

Photo by Nicolas Hoizey on Unsplash
8 — We remove nulls.
There is never a valid reason to use null. Null does not exist in real life.
It violates the principle of bijection and generates coupling between the function caller and the argument. Also, it generates unnecessary ifs as null is not polymorphic with any other object.
We change the absence of the argument to a boolean truth value.
9 — We remove the default parameters.
The private function in the previous example has a default parameter.
Default parameters produce coupling and ripple effect. They are available for the programmer laziness. Since it is a private function the replacement scope is the same class. We make it explicit, replacing all invocations:
10 — We remove hard coded constants.
These constants coupled within the code will not allow us to make good tests “manipulating time”.
Remember that the tests have to be in control of the entire environment and the time is global and fragile to match the tests.
From now on, it will be an essential parameter of object creation (Refactoring by adding parameters is a safe task, which can be done by any modern IDE.
11 — We decouple the log.
The log stores relevant information in production about the executions of the strategy. As usual, using a Singleton as a global reference.
This new bond prevents us from being able to test it. This Singleton is in another module over which we have no control, so we are going to use a wrapping technique.
Besides from being a Singleton, the log uses static class messages.
Let’s remember that:
The only protocol that a class should contain is the one related to its single responsibility (the S for Solid): creating instances.
Since the reference is to a static method, we cannot replace the class call with a polymorphic method. Instead, we will use an anonymous function.
Then, we can decouple the reference to the log and extract it from the class by reducing the coupling, generating better cohesion from the strategy and favoring its testability.
We can now use the object with several different kind of loggers (like tests doubles).
With the call from the productive code:
And the call from the tests:
12 — We reify objects.
On the way of our refactoring we find some fixes with persistent data. Such data travel cohesively, so it makes sense to think of it as an object with real-world responsibilities:
By creating the new concept, we are in danger of building an anemic model. Let’s see what hidden responsibilities you have:
13 — We complete the coverage.
We did not forget to program the tests that we could not write at the beginning. As we have a much less coupled design it is now very easy to do.
And our system is much less “legacy” compared to when we found it.

Photo by Kelly Sikkema on Unsplash
Summary
After hard iterative and incremental work, through short steps, we have achieved a better solution in the following aspects:
- Less Coupling.
- Immutability.
- Better Names.
- No Setters / Getters.
- No Ifs.
- Without Null.
- Without Singletons.
- No default parameters.
- Better test coverage.
- Following the Open/Closed principle (Solid’s O) to be able to add new polymorphic algorithms.
- Following the principle of Single Responsibility (The S for Solid).
- Without overloading the classes with protocol.

Photo by Zac Farmer on Unsplash
Conclusions
Modifying an existing system by improving its design is possible, taking into account clear design rules and taking small steps. We must have professional responsibility and courage to make the relevant changes, leaving a much better solution than when we found it.
We can even make TDD on legacy systems using these techniques.
Part of the objective of this series of articles is to generate spaces for debate and discussion on software design.
We look forward to comments and suggestions on this article.
This article is also available in Spanish here.