Nude Models — Part II : Getters

I’m a senior software engineer loving clean code, and declarative designs. S.O.L.I.D. and agile methodologies fan.
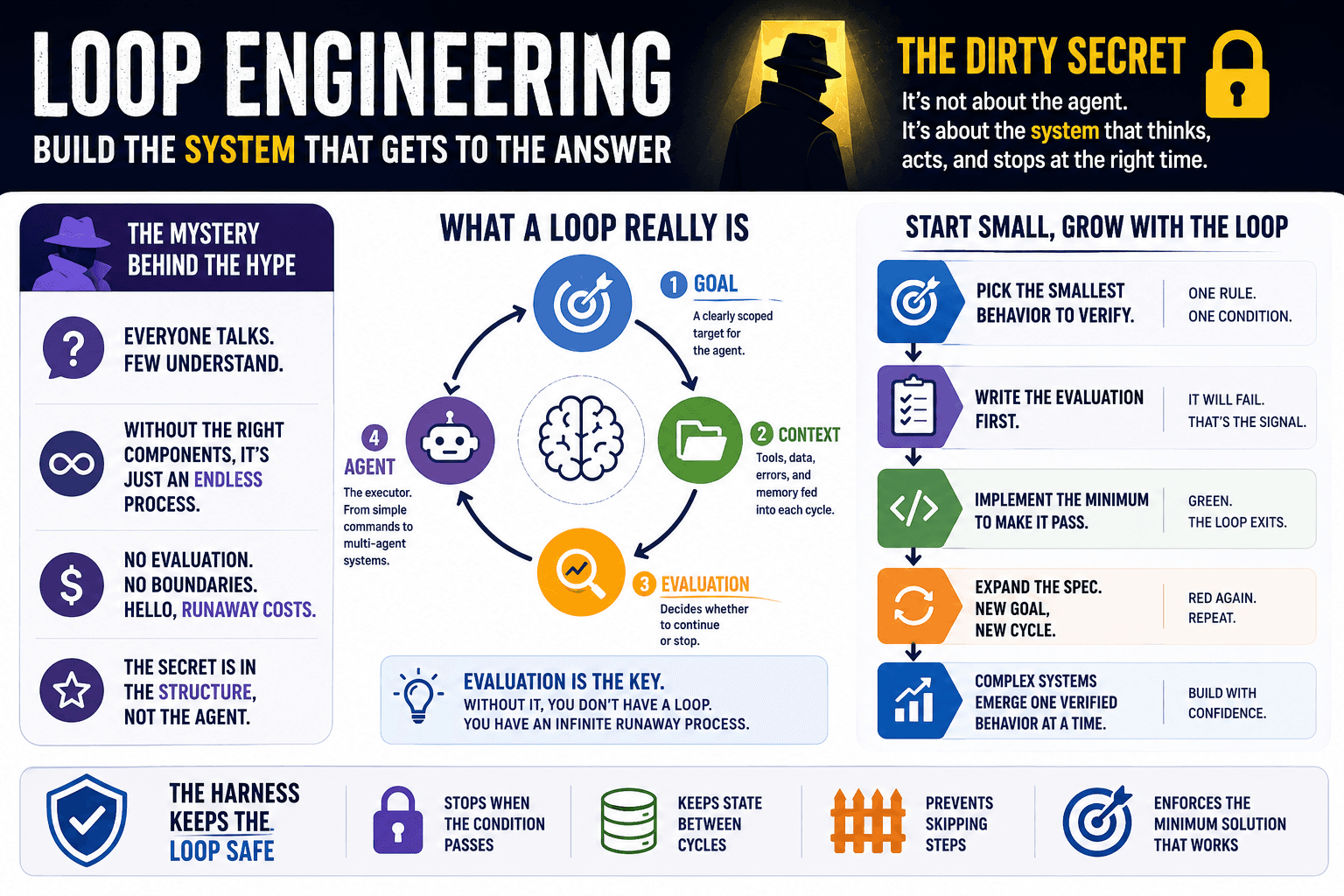
Ye olde Reliable Data Structures and Their Controversial (Read) Access.
Using objects as data structures is an established practice that generates many problems associated with the maintainability and evolution of software. It misuses brilliant concepts that were stated five decades ago. In this second part we will reflect on the reading access of these objects.
In the first part of this article, we showed the transition from hidden information in data structures towards living objects responsibilities (the essential what) hiding the implementation (the accidental how).
In this second part, we will show the drawbacks of using getters.
 Photo by Dominik Vanyi on Unsplash
Photo by Dominik Vanyi on Unsplash
The name that does not exist in real world (Reprise)
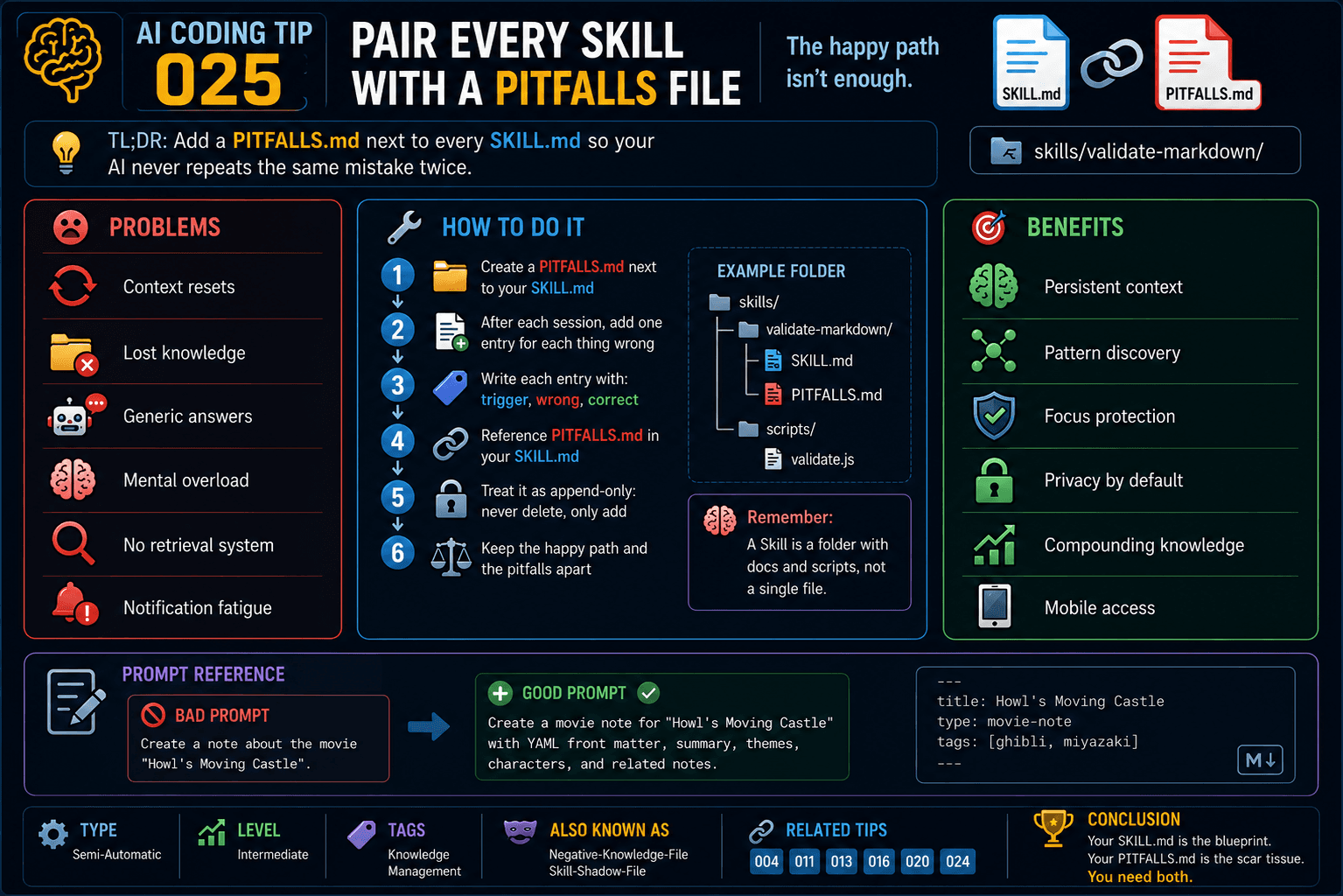
Programmers conventionally use the names of the form getAttribute…() to expose (and lose control of) a previously private attribute. Due to the same arguments stated on setter’s article, this name cannot be mapped to a real-world equivalent through bijection.
The final conclusion regarding these names is:
There should never be methods of the form setAttribute…() or getAttribute…()
Do not expose collections
Many objects manage collections. The contents management, the invariants or the traversal method should be the sole responsibility of these objects.
Suppose we want to draw the polygon presented on Part I, on a canvas. We will achieve it with the following code:
Drawing a Polygon
By exposing the vertices collection (and since collections are passed by reference in most languages) we lose control over that collection.
Nothing prevents this other code from running:
array_shift () removes the first value from the array
This causes the triangle to mutate, generating an inconsistency real world bijection. Two-sided polygons would violate the principle of being a closed figure.
This defect will be noticed a long time later because it has not been detected in time, thus violating the fail fast principle.
In no case shall such objects expose their collections, thus enforcing Demeter’s law.
In case you need to return the collected elements, you should answer with a copy (shallow) to avoid losing control. With the current state of the art, copying collections is extremely fast. If they were very large collections, there are design solutions with iterators, proxies and cursors to avoid performing the full copy operation.
Iterating collections
How do we solve the polygon draw operation ?
Iterating a collection is a well-known topic when working with design patterns:
If we want to go around our polygon, we can return an iterator (indicating what we need to do) without revealing our underlying data structure (how we traverse it).
Returning an iterator allows the object to change its representation
In case of languages supporting anonymous functions or closures), we could take the responsibility of iterating elements without exposing an iterator outwards:
Mutating collections
Polygons must not mutate because vertices are part of their minimal essence: if we remove any of their vertices, they are no longer that polygon that makes them unique.
There are many business objects that can mutate in their accidental collections and there are mechanisms to manage such mutations.
If we wanted to model a Twitter account and keep its followers, knowing the business rules, the account is created without followers.
let’s ignore the suggestions that it offers us when creating the new account.
Using setters and getters, a novice programmer would be tempted to add a follower in this way:
A correct responsibility assignment guided by business rules suggests that it is the account’s responsibility to add a new follower, carry out validations (for example, that it is was not followed previously) and keep collection integrity.
Therefore, a better solution would be:
Double encapsulation
In the 90s there was a tendency to create a double encapsulation of attributes as an extreme approach on privacy. This means that, even from the private methods of an object, direct access to variables would be avoided.
This practice does not generate any benefits. Adds unnecessary indirection, and expose setters and getters in languages that have no distinction between public and private methods.
In addition, it hides the coupling between an attribute and the direct methods that reference it, avoiding possible refactorings.
Tell, don’t ask
There is a principle that states:
Don’t ask for the information you need to get the job done; ask the object that has the information to do the work for you
This principle is known as: Tell, don’t ask.
It reminds us that, instead of requesting data from an object and acting on this data, we should tell an object what to do. This encourages movement of behavior along with the knowledge that the object is responsible for managing.
Too much information can kill us
Paraphrasing Demeter’s Law and minimum coupling and maximum cohesion laws:
- Each unit should have limited knowledge of others and only know those units closely related to itself.
- Each unit should speak only to its friends and not speak to strangers.
- Just talk to your immediate friends.
Adding accidental complexity with setters and getters implies generating coupling, violating these rules and generating a greater ripple effect in case of possible changes.
 Photo by Macau Photo Agency on Unsplash
Photo by Macau Photo Agency on Unsplash
Setters and getters violate anthropomorphism
Let’s go back to our only design rule that asks for a bijection between the model we are building and the real world and respecting the principle of Anthropomorphism (giving a living entity to each object).
In doing so, we will discover that the responsibilities we give to objects after they have been returned with a getter do not map with the real world violating bijection.
On this page there is an excellent example of disrespected anthropomorphism when using getters.
Changing the way we think
When we start to model our objects forgetting about their accidental representation, we will be able to avoid anemic classes (which only fulfill the function of saving data, resulting in a well-known anti-pattern).
As with data structures, there is no way for an anemic class to guarantee the integrity of your data and relationships.
Since operations on anemic classes are outside of anemic classes boundaries there is no single point of control. Therefore, we will generate both repeated code and access points to these attributes that exist in our model. We will always pursue to emulate the behavior of objects like black boxes, getting much more realistic and declarative bijections.
Recommendations
- Do not use setters. There are no well-reasoned reasons for doing so.
- Don’t use getters. In case any of the responsibilities of an object is related to responding to a message matching an attribute, do it thinking beforehand if we are not breaking the encapsulation.
- Never prefix the function name with the word get. If a polygon in the real world can answer what its vertices are, be it with the real world name (vertices()).
- In case of returning collections, return a copy or a proxy so as not to lose control and favor the use of iterators.
- Have no public attributes. For practical purposes it is like having setters and getters. It is also a code smell of anemic objects.
- Have no public static attributes. In addition to what is listed above the classes should be stateless and this is a code smell indicating that a class is being used as a global variable.
Transition from a legacy code system
Not all is bad news. Converting a bad model into a good one is possible through a correct responsibilities reassignment, and with the help of the appropriate refactors.
If we have the opportunity of improving a system with good coverage, we can gradually encapsulate the objects, restricting their access in an incremental iterative way.
In case of not having enough coverage we will be in front of a legacy code system according to the excellent definition of Michael Feathers:
A legacy code system is one that has no coverage.
Should this be the case, we must first cover the existing functionality, and then we can carry out the necessary transformations.
 Photo by Greg Nunes on Unsplash
Photo by Greg Nunes on Unsplash
Conclusions
The well established practice of using setters and getters generates coupling and prevents the incremental evolution of our computer systems.
According to the arguments stated in this article, we should restrict their use as much as possible.
Part of the objective of this series of articles is to generate spaces for debate and discussion on software design.
We look forward to comments and suggestions on this article.
This article is also available in Spanish here.